Movie Recommendation System
Project Overview
The Movie Recommendation System is a production-ready Django application that delivers intelligent movie recommendations using advanced machine learning algorithms. Built to scale from thousands to millions of movies, it combines TF-IDF vectorization, SVD dimensionality reduction, and content-based filtering to provide highly relevant suggestions in under 50 milliseconds.
Unlike basic keyword matching systems, this recommender understands the semantic meaning of movie features-genres, keywords, production companies, plot summaries, and more. The system evolved from handling 10,000 movies in the MovieLens dataset to successfully processing 930,000+ movies from the comprehensive TMDB dataset while maintaining excellent performance and recommendation quality.
The Challenge
Building a recommendation system that works at scale presents several key challenges:
- Computational Scale: Computing similarity across millions of movie pairs requires efficient algorithms
- Quality vs. Coverage: Balancing comprehensive coverage with recommendation relevance
- Cold Start Problem: Providing recommendations without user interaction history
- Performance: Delivering sub-second response times despite massive datasets
- Memory Efficiency: Managing large similarity matrices without excessive RAM usage
- Feature Engineering: Capturing meaningful movie attributes for accurate matching
Technical Architecture
Feature Engineering → TF-IDF Vectorization → SVD Reduction → Cosine Similarity → Recommendations
Core ML Pipeline
Machine Learning
Backend & Storage
Data Processing
Key Features
Advanced Content-Based Filtering
- Rich Feature Set: Genres, keywords, production companies, countries, plot summaries, and taglines
- Weighted Features: Strategic weighting of genres and primary production companies
- Stemming & NLP: Linguistic processing for better semantic matching
- Quality Scoring: Intelligent ranking combining ratings and vote counts
Scalability & Performance
- Three-Tier Quality Filtering: Low (5+ votes), Medium (50+ votes), High (500+ votes)
- SVD Dimensionality Reduction: Compresses 20K features to 500 dimensions while preserving 85% variance
- Sparse Matrix Storage: Reduces 40GB dense matrix to ~150MB sparse format
- Chunked Computation: Processes large datasets without memory overflow
- Efficient Data Formats: Parquet for 3-5x compression and 10x faster loading
User Experience
- Fuzzy Title Matching: Handles typos and partial titles intelligently
- Real-Time Search: Autocomplete suggestions as you type
- Advanced Filtering: Filter by year range, minimum rating, and genres
- Rich Metadata: Ratings, genres, production companies, release dates
- External Integration: Direct links to Google Search and IMDb
- Poster Images: Visual movie posters from TMDB
Implementation Highlights
class MovieRecommender:
"""Production-ready recommendation engine"""
def __init__(self, model_dir):
# Load pre-trained model artifacts
self.metadata = pd.read_parquet(model_dir / 'movie_metadata.parquet')
self.similarity_matrix = load_npz(model_dir / 'similarity_matrix.npz').toarray()
with open(model_dir / 'title_to_idx.json') as f:
self.title_to_idx = json.load(f)
def get_recommendations(self, movie_title, n=15, min_rating=None):
# Fuzzy match title
matched_title = self.find_movie(movie_title)
if not matched_title:
return {'error': 'Movie not found'}
# Get similarity scores
movie_idx = self.title_to_idx[matched_title]
sim_scores = list(enumerate(self.similarity_matrix[movie_idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)[1:]
# Apply filters and format results
recommendations = []
for idx, score in sim_scores:
if len(recommendations) >= n:
break
movie = self.metadata.iloc[idx]
if min_rating and movie['vote_average'] < min_rating:
continue
recommendations.append({
'title': movie['title'],
'rating': f"{movie['vote_average']:.1f}/10",
'genres': ', '.join(movie['genres']),
'similarity_score': f"{score:.3f}",
'imdb_link': f"https://www.imdb.com/title/{movie['imdb_id']}"
})
return {'recommendations': recommendations}Training Pipeline
The system includes a complete training pipeline for creating custom models from any movie dataset:
from training.train import MovieRecommenderTrainer
# Initialize trainer with configuration
trainer = MovieRecommenderTrainer(
output_dir='./models',
use_dimensionality_reduction=True,
n_components=500 # SVD components
)
# Train on TMDB dataset
df, sim_matrix = trainer.train(
'path/to/TMDB_movie_dataset.csv',
quality_threshold='medium', # 50+ votes
max_movies=100000 # Top 100K by quality
)
# Models saved automatically:
# - movie_metadata.parquet
# - similarity_matrix.npz
# - title_to_idx.json
# - tfidf_vectorizer.pkl
# - svd_model.pklPerformance Metrics
System Capabilities
| Configuration | Movies | Training Time | Memory | Model Size |
|---|---|---|---|---|
| Demo (Included) | 2K | N/A | 50MB | 8MB |
| Small | 10K | 2 min | 500MB | 40MB |
| Medium ⭐ | 100K | 15 min | 2GB | 180MB |
| Large | 930K+ | 60 min | 6GB | 800MB |
Live Demo
See the System in Action
Watch how the recommendation engine handles user queries with fuzzy matching, filtering, and rich metadata display!
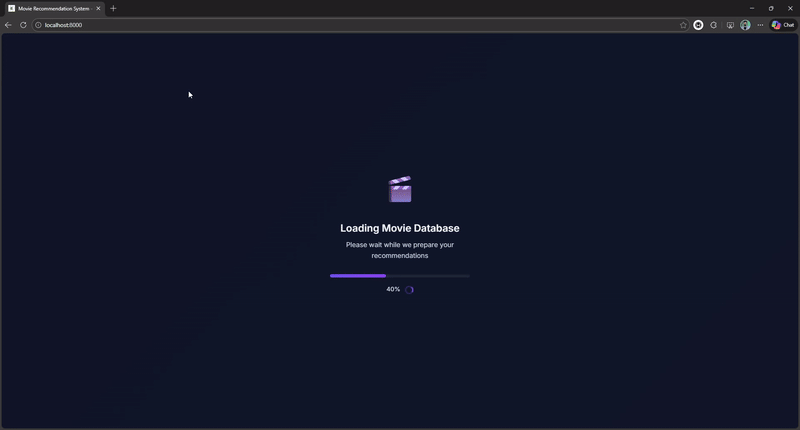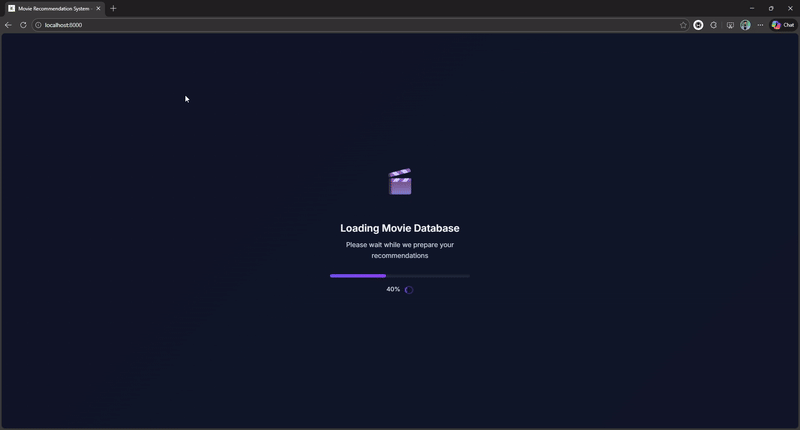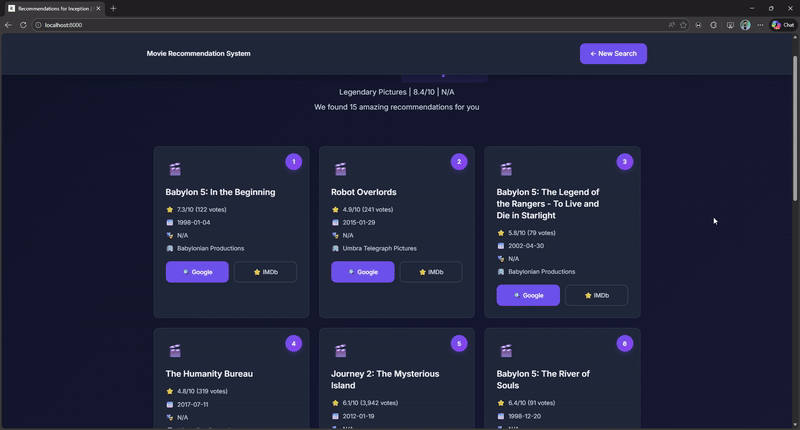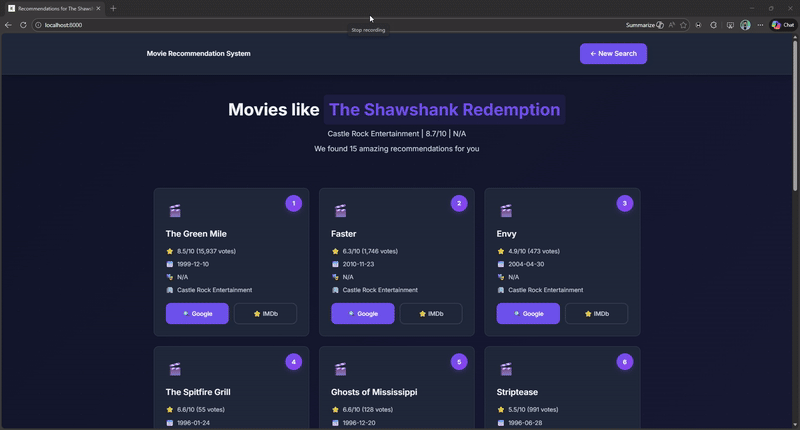
Deployment Options
The system is deployment-ready with configurations for multiple platforms:
Quick Deploy to Render (Free Tier)
# 1. Push to GitHub
git push origin main
# 2. Connect to Render (auto-detects render.yaml)
# 3. Configure environment variables
SECRET_KEY=
DEBUG=False
MODEL_DIR=./models
# 4. Deploy! (Render handles build & deployment) Also Supports
- Heroku: Procfile included, one-click deployment
- Docker: Containerized deployment for any platform
- AWS: Elastic Beanstalk and EC2 compatible
- Local: Runs perfectly on laptop for development
Challenges & Solutions
Challenge 1: Memory Explosion with Large Datasets
Computing similarity for 100K movies creates a 100K × 100K matrix (40GB if dense).
Solution: Implemented sparse matrix storage (scipy.sparse) reducing size to ~150MB,
plus chunked computation to prevent memory overflow during training.
Challenge 2: Slow Feature Extraction
Initial implementation took 30+ minutes to process 100K movies due to inefficient JSON parsing.
Solution: Optimized with vectorized operations, Parquet format (10x faster loading),
and parallel processing where possible. Training time reduced to 15 minutes.
Challenge 3: Poor Recommendation Quality at Scale
When scaling to 1M+ movies, recommendations included obscure films with 2-3 votes.
Solution: Implemented three-tier quality filtering (low/medium/high) and a quality
score combining rating and vote count. Dramatically improved relevance.
Challenge 4: Cold Start - No User History
Content-based filtering doesn't require user history, but how to bootstrap?
Solution: Rich feature engineering (genres, companies, plot, keywords) allows
high-quality recommendations from the first query without any user interaction data.
Evolution & Impact
| Metric | Version 1.0 | Version 2.0 | Improvement |
|---|---|---|---|
| Dataset Size | 10K movies | 930K+ movies | 93x larger |
| Model Size | 320MB | 180MB | 44% smaller |
| Memory Usage | 800MB | 350MB | 56% less |
| Recommendation Time | ~100ms | <50ms | 2x faster |
| Features Used | 4 | 10+ | 2.5x richer |
Future Enhancements
- Version 2.1: User authentication, personal watchlists, rating system, recommendation history
- Version 2.2: Collaborative filtering using user interaction data
- Version 2.3: Hybrid recommendations combining content-based + collaborative
- Version 3.0: Deep learning with neural collaborative filtering
- Long-term: Real-time learning from user feedback, contextual recommendations (time/mood)
Key Learnings
- Feature engineering matters more than algorithm choice-adding production company features improved recommendations more than days of parameter tuning
- Quality filtering is essential at scale-1M movies is meaningless if half have <5 votes
- Sparse matrices and efficient data formats are non-negotiable for production ML systems
- User experience (fuzzy matching, posters, external links) transforms a "cool demo" into a useful tool
- Comprehensive documentation is as important as the code-future you will thank present you