FIFA Player Recommendation System
Project Overview
This is a web-based player recommendation system built on FC 25 FIFA stats. You search for a player, and the app finds the most similar players from the dataset using their in-game attributes. It supports both male and female players, lets you compare up to four players side by side, and visualizes the comparisons using radar charts.
The app runs entirely in the browser against a Flask backend. There is no database - all recommendations come from a precomputed similarity model built at training time and loaded into memory at startup.
Why I Built This
I built this as a side project to work on something concrete with recommender systems. Most tutorials on recommendation engines use movies or books. I wanted to apply the same ideas to a domain that is more interesting to me, and one where the features are richer and more structured.
This project also gave me a reason to build a full end-to-end ML system from scratch: data cleaning, feature engineering, model training, a REST API, and a frontend. I published it open source so that other developers learning about content-based filtering or ML systems have a real working example they can read, run, and modify.
The Problem
Finding players with similar play styles in FIFA is not straightforward. The game has hundreds of attributes per player, and comparing them manually does not scale.
This project reduces that problem by:
- Computing how similar any two players are across 34 key attributes
- Giving you the top N most similar players for any player you search
- Letting you compare multiple players visually with radar charts
- Supporting filters like position category and age gap so results stay relevant
It is a practical example of how content-based filtering works when your "items" have structured numeric features.
Key Features
Player Search
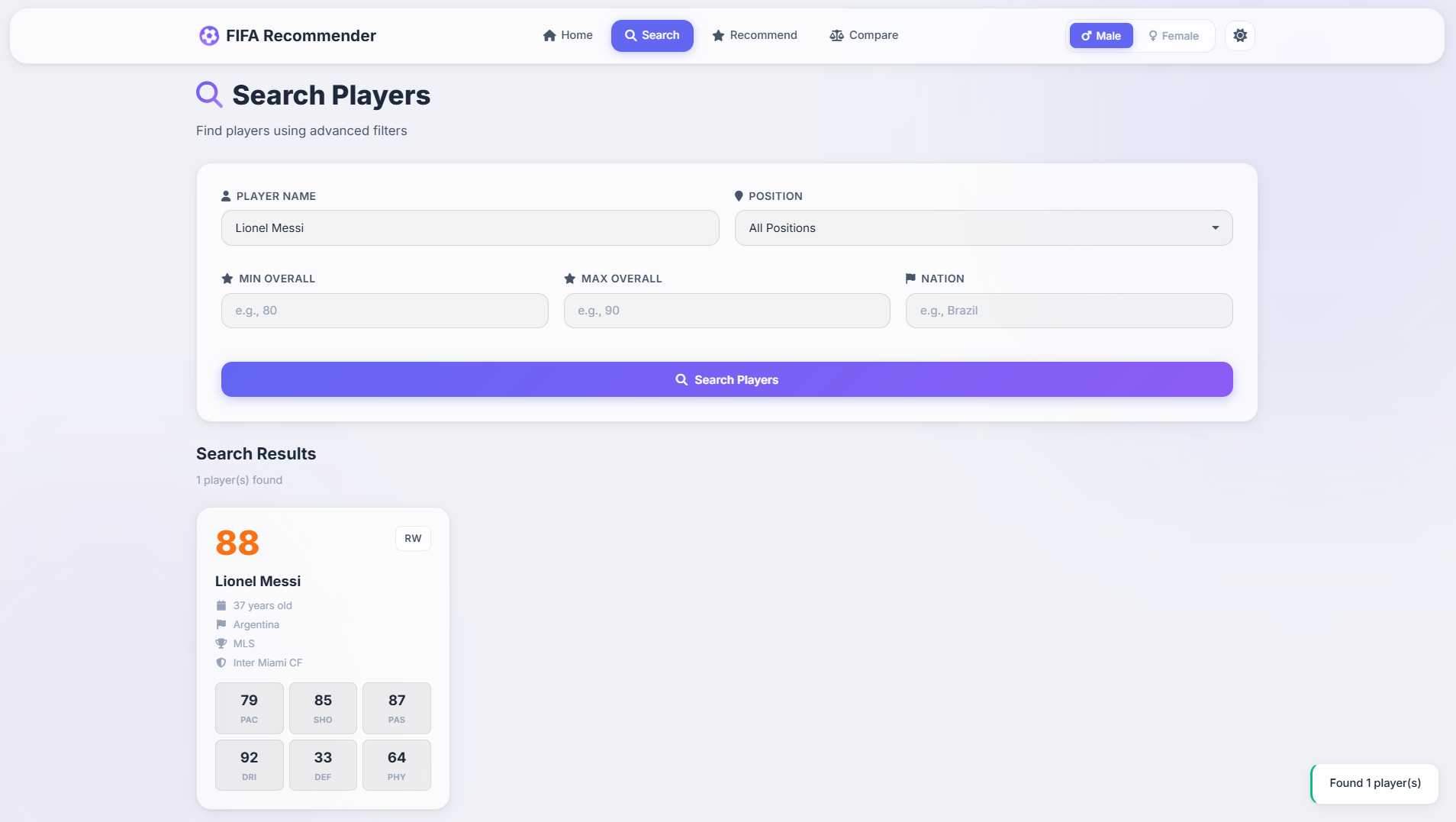
Search with filters for name, position, overall rating, nationality, league, and team. Autocomplete for player name lookups.
Similarity Recommendations
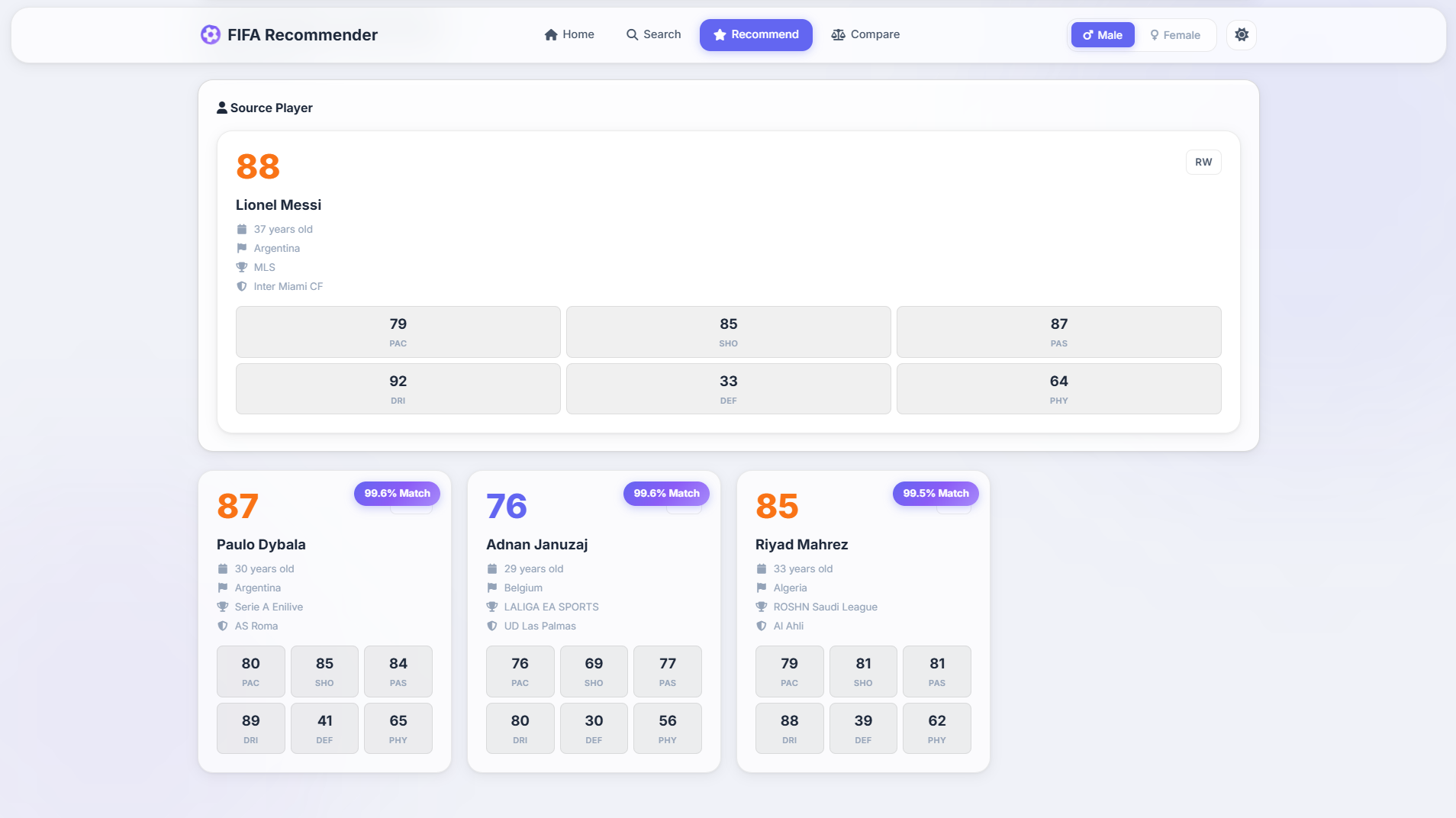
Cosine similarity on 34 player attributes returns the top N most similar players for any input player.
Gender Toggle
Separate trained models for male and female players. Switch between them with a single toggle for fully isolated results.
Multi-Player Comparison
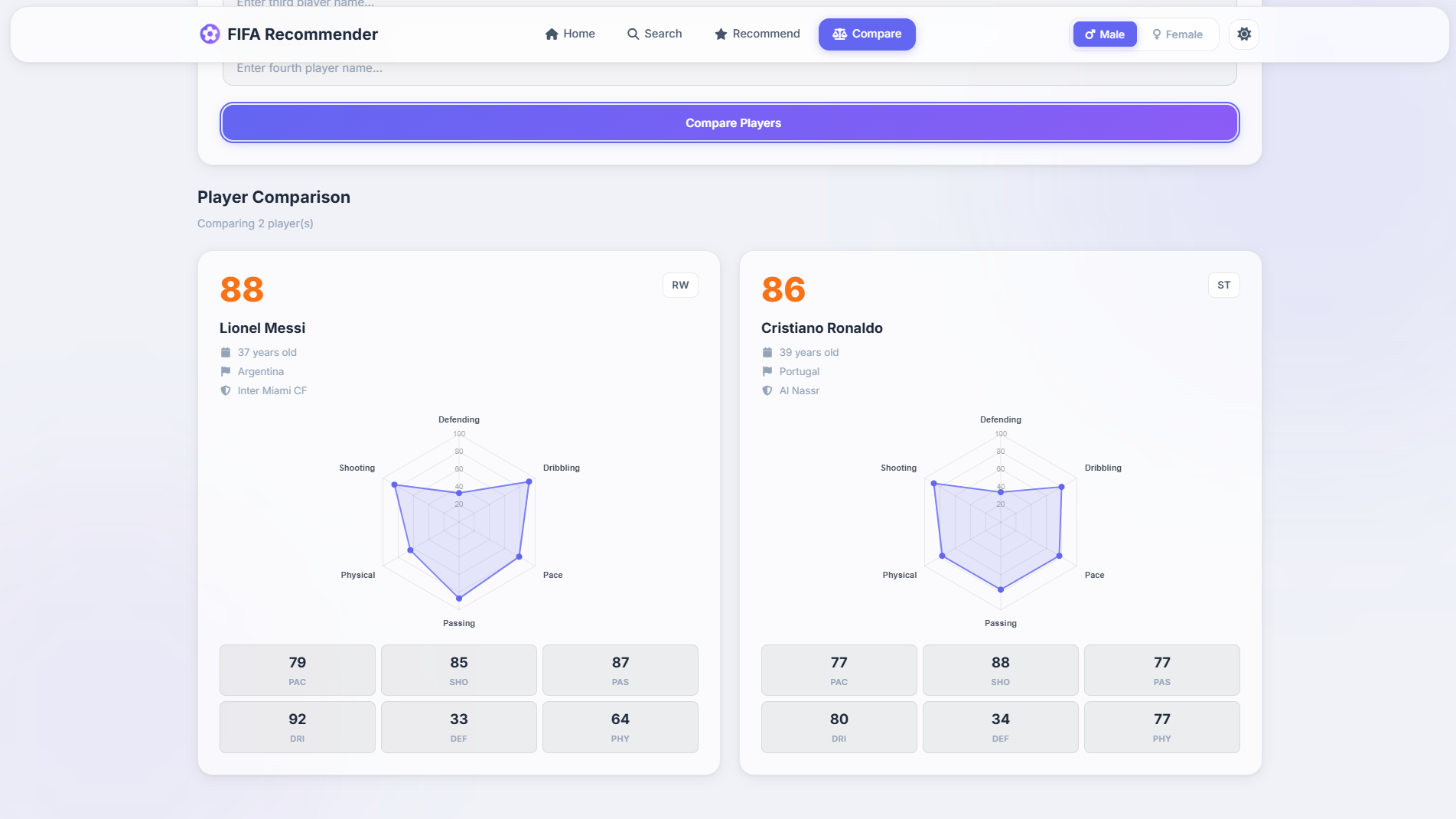
Compare 2 to 4 players at once with a side-by-side radar chart overlay - great for scouting alternatives.
Player Detail View
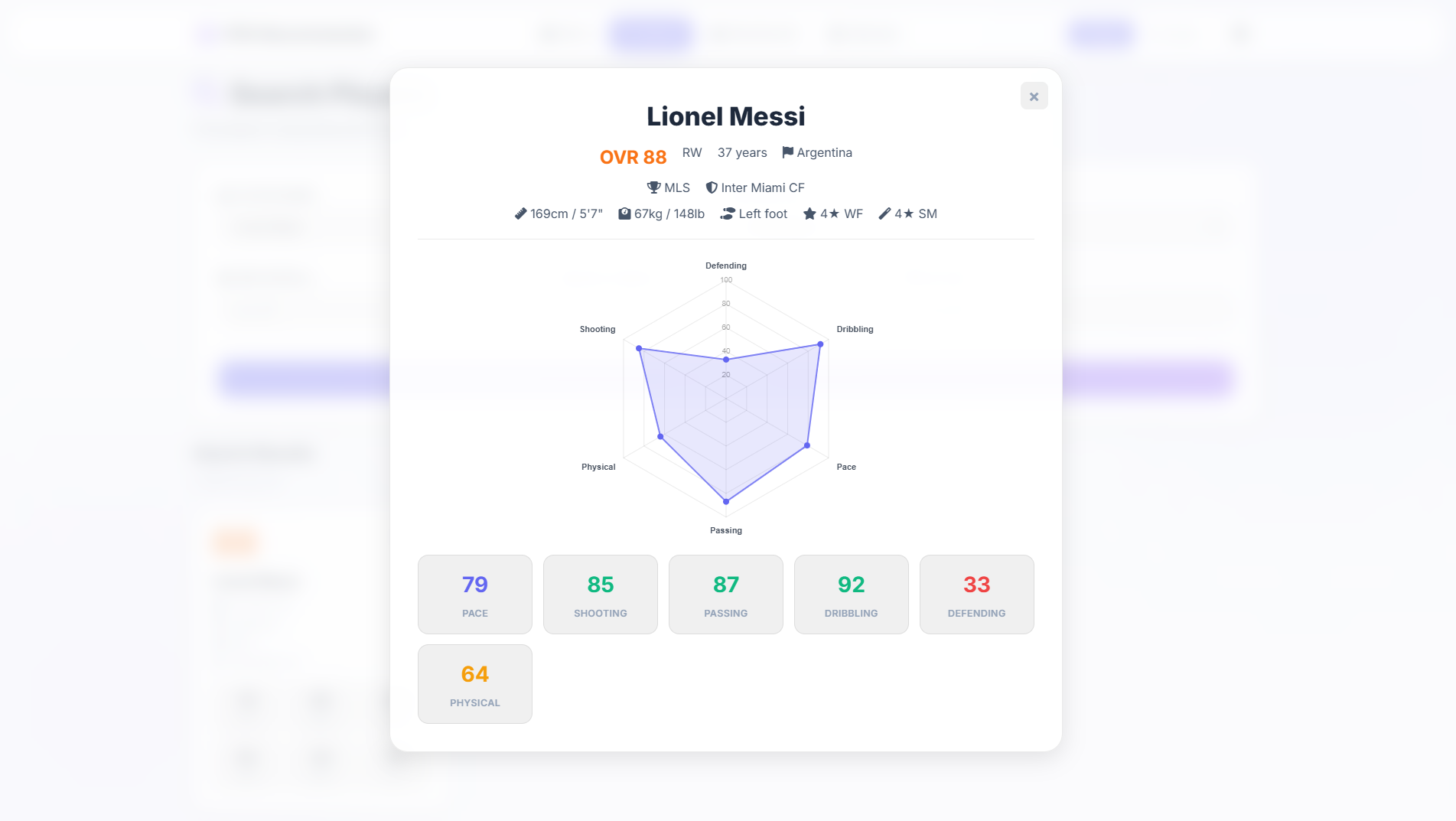
Individual stats cards with a dedicated radar chart per player, showing all 34 attributes at a glance.
Top Players & Stats
Browse top-rated players and dataset statistics directly from the UI - no manual CSV digging required.
How It Works
The system is split into an offline training phase and an online serving phase. The heavy computation happens once at training time so that every query at runtime is just a fast array lookup.
- Data preparation: The training script reads a CSV file of FC 25 player stats, cleans the data, removes duplicates, and assigns each player a position category.
- Feature extraction: 34 numeric attributes are selected per player - pace, shooting, passing, dribbling, defending, and specific sub-stats like sprint speed, vision, and composure.
- Normalization: Each player's feature vector is min-max normalized so all attributes contribute equally to the similarity score.
- Similarity matrix: The full pairwise cosine similarity matrix is precomputed over all players. The matrix, the original DataFrame, and feature names are bundled and saved as a
.pklfile usingjoblib. - Serving: At startup, Flask loads the pickled models into memory. All API calls work against this in-memory data - no live database.
- Recommendation: When you request similar players, the app reads the player's similarity row, applies optional position and age filters, and returns the top N results sorted by score.
- Frontend: A single-page HTML/JS app calls the Flask JSON API and renders results using Chart.js radar charts.
Screenshots
Home Page (Light Theme)
Home Page (Dark Theme)
Player Search
Player Recommendations
Player Profile View
Compare Players
Tech Stack
Backend
Frontend
Data
ML
Core Code Snippets
The 34 attributes used to measure player similarity
These features form the input vectors for cosine similarity. Every recommendation comes down to how close two players' normalized versions of these values are.
FEATURE_COLUMNS = [
'PAC', 'SHO', 'PAS', 'DRI', 'DEF', 'PHY',
'Acceleration', 'Sprint Speed', 'Positioning', 'Finishing',
'Shot Power', 'Long Shots', 'Volleys', 'Penalties',
'Vision', 'Crossing', 'Free Kick Accuracy', 'Short Passing',
'Long Passing', 'Curve', 'Dribbling', 'Agility', 'Balance',
'Reactions', 'Ball Control', 'Composure', 'Interceptions',
'Heading Accuracy', 'Def Awareness', 'Standing Tackle',
'Sliding Tackle', 'Jumping', 'Stamina', 'Strength', 'Aggression'
]Precomputing the full similarity matrix at training time
This is a deliberate trade-off: spend time and memory once at training so that every recommendation at query time is just an array lookup.
# Precompute similarity matrix for fast recommendations
print("Computing similarity matrix...")
self.similarity_matrix = cosine_similarity(normalized_features)
print(f"Similarity matrix computed: {self.similarity_matrix.shape}")Filtering and ranking recommendations
After reading the similarity row for a player, the system skips the player itself, applies optional position and age filters, and returns the top N results sorted by score.
similarity_scores = self.similarity_matrix[player_idx]
for idx, score in enumerate(similarity_scores):
if idx == player_idx: # Skip the player itself
continue
if same_position and player_position:
if candidate.get('Position_Category') != player_position:
continue
# ... age gap filter applied here ...
candidates.sort(key=lambda x: x[1], reverse=True)
for idx, score in candidates[:n_recommendations]:
# build and return result listMy Contribution
I designed and built this project end to end:
- Defined the feature set and data processing pipeline for both male and female player datasets
- Built the
DataProcessorandPlayerRecommenderclasses from scratch - Implemented the cosine similarity-based recommendation logic with position and age filtering
- Wrote the Flask REST API with all search, recommend, compare, and stats endpoints
- Designed and built the single-page frontend with Chart.js radar charts
- Set up packaging, training scripts, and documentation
Challenges & Learnings
Scaling the similarity matrix
The precomputed similarity matrix is O(n²) in memory. For a large player dataset, this gets heavy fast.
I kept it as a deliberate design choice for query speed, but it made me think carefully about when this
trade-off makes sense versus using approximate nearest neighbor methods like FAISS or Annoy.
Consistent normalization between training and inference
When I added a feature to recommend players by custom attribute values (not from the dataset), I had
to ensure the input was normalized the same way as the training data. It is easy to get this subtly
wrong, and the recommendations would silently degrade without an obvious error.
Name resolution ambiguity
Player names in the CSV are not always unique or clean. The lookup function falls back to substring
matching, which means it can return a different player than intended. Handling name resolution reliably
turned out to be trickier than expected.
Separating male and female models cleanly
The two player pools have different data distributions. Keeping them as completely separate trained
models was the simplest and most reliable approach, even though it doubles the memory footprint at
runtime.
Future Improvements
- Replace the precomputed O(n²) matrix with an approximate nearest neighbor index (FAISS or Annoy) to reduce memory and support larger datasets
- Add a proper name normalization step so player lookups are more reliable
- Support dataset updates without retraining from scratch
- Add a Docker setup for easier one-command deployment
- Expose a simple public API so other developers can build on top of the recommendation engine
Closing Note
This project is fully open source under the MIT license. It was built as a personal learning project and shared so others can use it, study it, or improve it. If you find it useful, run into a bug, or have an idea to make it better, feel free to open an issue or a pull request on GitHub.
It is a practical, working example of how content-based filtering applies beyond the typical movies or books domain - if your items have structured numeric features, cosine similarity is a powerful and surprisingly interpretable baseline.