If you've ever tried to find something in a long PDF or a folder full of documents, you know how painful keyword search can be. You type a word, and you get dozens of hits that contain the word but don't really understand what you mean.
The Context Search Engine project was built to solve exactly that problem—and to serve as a learning lab for modern semantic search. In this post, we'll walk through what the project does, how it's built, and how you can use it to understand and experiment with semantic search end to end.
Why I Built This Project
I didn't want just another search demo. I wanted:
- A complete pipeline: upload documents → extract text → chunk → embed → index → search → explain.
- A Google-style interface that feels familiar, but powered by embeddings instead of keywords.
- A playground for students, researchers, and developers to learn, tweak, and break things safely.
So the objective of Context Search Engine is two-fold:
- Practical: Provide a local, privacy-friendly semantic search engine for PDFs, Word docs, and text files.
- Educational: Expose the entire semantic search pipeline so you can understand, debug, and experiment.
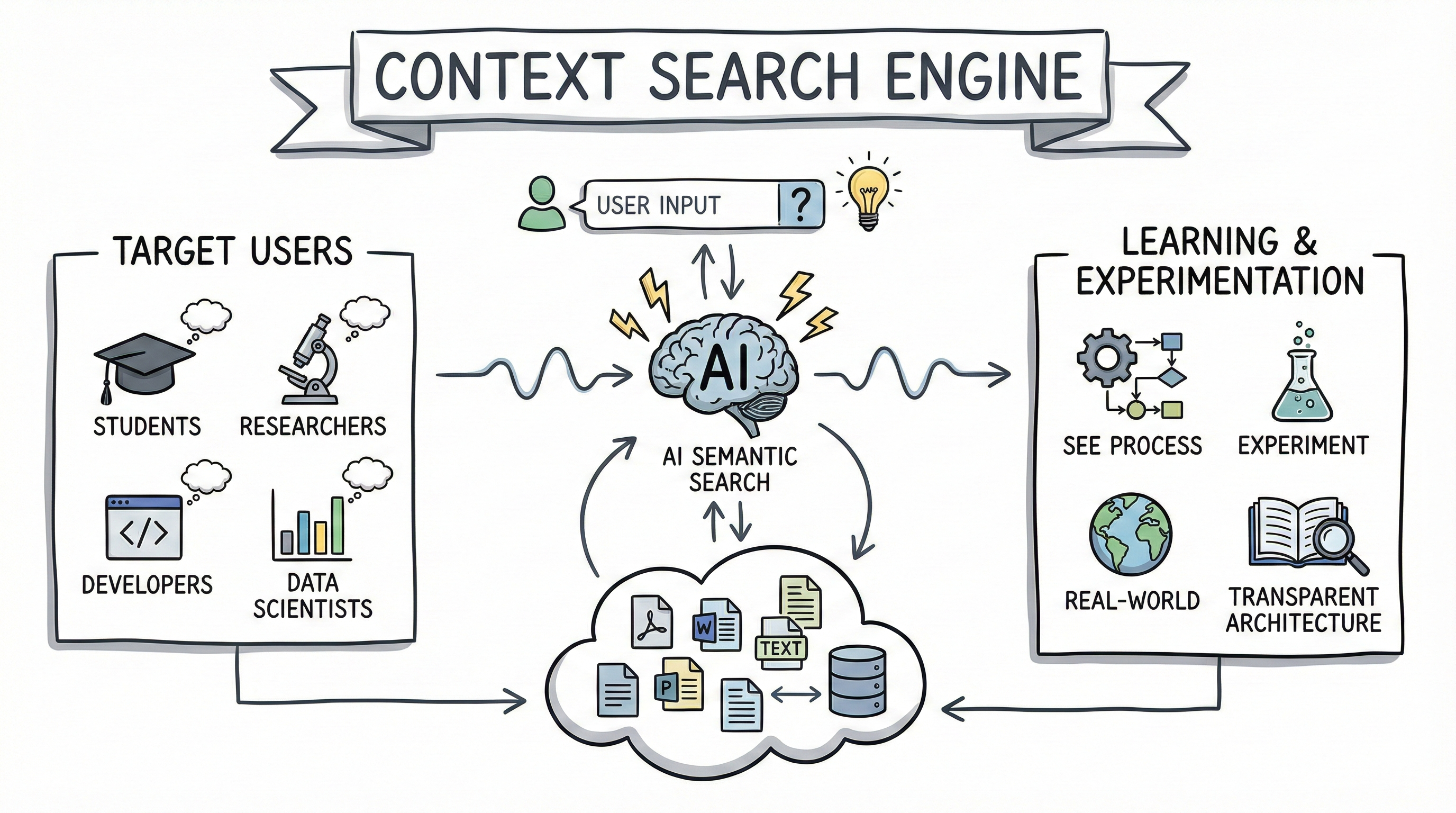
Who This Project Is For
- Students & College Grads
Learn what embeddings, FAISS, and semantic search actually do by playing with real documents and queries. - Researchers
Test different chunking strategies, overlap sizes, and models on your own domain-specific corpora. - Developers & Data Scientists
Use it as a microservice, a prototype, or a reference implementation for document search in your own apps.
The User Experience: A Google-Style Search Lab
When you run the app and open it in your browser (http://localhost:5000), you get a
clean, centered search box—very similar to Google.
From there, you can:
- Upload Documents: Drag-and-drop PDFs, DOCX, or TXT files.
- Configure the Engine: Choose your embedding model, chunk size, overlap, and search parameters.
- Manage Documents: View and delete existing documents through a simple dashboard.
- Search Semantically: Type at least 3 characters and see results update with a slight delay (500ms debounce).
Each search result includes:
- Rank (#1, #2, …)
- Document name
- Page number (for PDFs)
- Chunk number
- Matched text snippet
- Relevance score
- A "View Source" button to jump back to context
High-Level Architecture
At a high level, the Context Search Engine works like this:
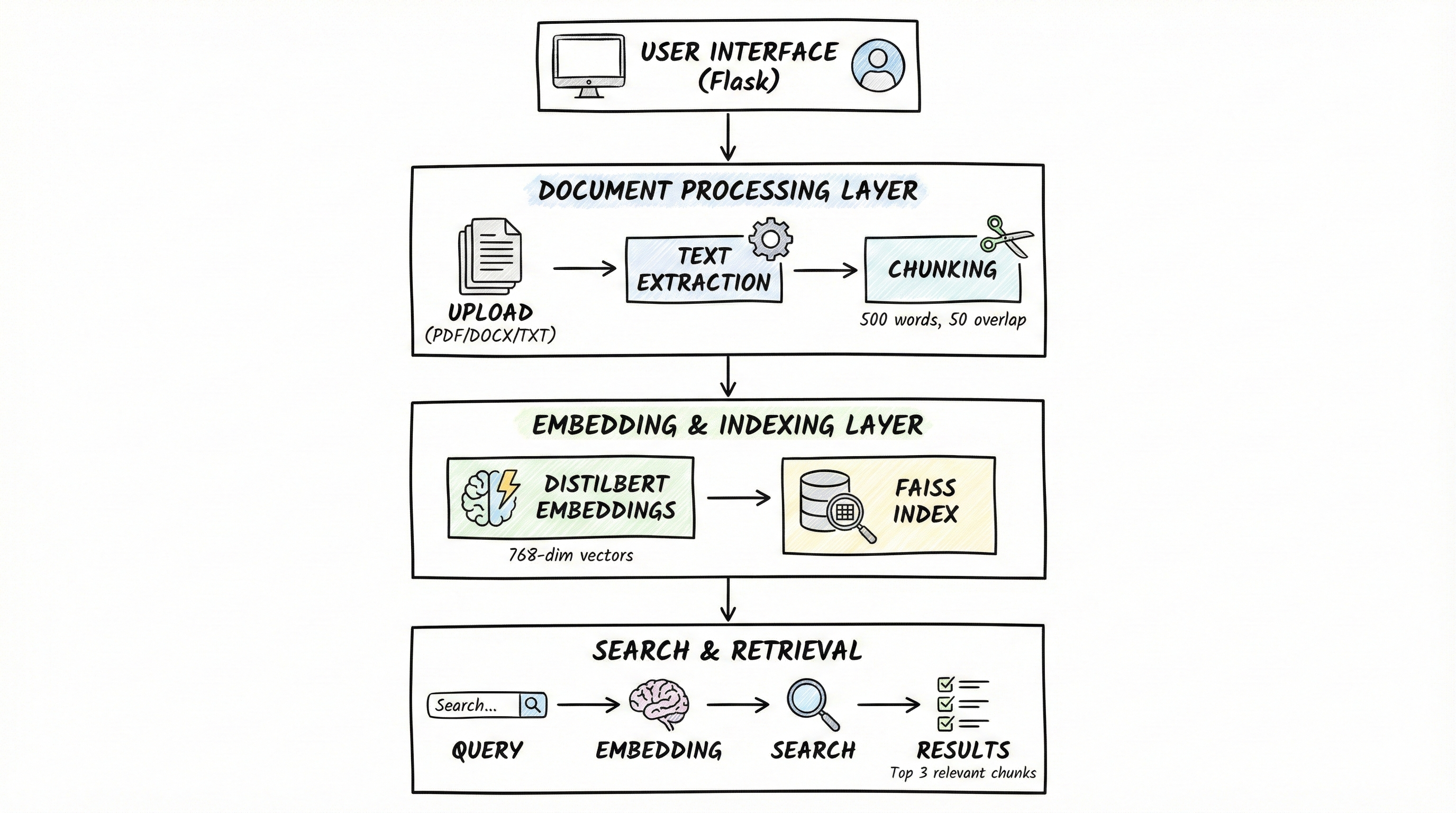
Upload → Extract → Chunk → Embed → Index → Search → Results
The Seven-Step Pipeline
| Step | What Happens | Technology |
|---|---|---|
| 1. Upload | User uploads files via web UI | Flask file handling |
| 2. Extract | Text extraction from documents | PyPDF2, python-docx |
| 3. Chunk | Split text with configurable overlap | Custom chunking logic |
| 4. Embed | Convert chunks to vectors | HuggingFace Transformers |
| 5. Index | Store vectors for fast search | FAISS |
| 6. Search | Find similar chunks for query | FAISS similarity search |
| 7. Results | Display with metadata | Web UI with ranking |
A Look at the Core Logic
At its heart, the engine is doing three things:
- Chunk the text into overlapping windows.
- Embed each chunk with a transformer model.
- Search with FAISS using the query embedding.
Here's a simplified, self-contained version of the core logic:
from typing import List, Dict, Any
import numpy as np
import faiss
import torch
from transformers import AutoTokenizer, AutoModel
class SemanticSearchEngine:
def __init__(self, model_name: str = "distilbert-base-uncased", dimension: int = 768):
self.model_name = model_name
self.dimension = dimension
# 1. Load model & tokenizer
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name)
# 2. Initialize FAISS index (L2 distance)
self.index = faiss.IndexFlatL2(dimension)
# 3. Keep metadata for each vector
self.metadata: Dict[int, Dict[str, Any]] = {}
self._next_id = 0Chunking Logic
Documents are split into overlapping chunks to preserve context at boundaries:
def _chunk_text(self, text: str, chunk_size: int = 500, overlap: int = 50) -> List[str]:
words = text.split()
chunks = []
start = 0
while start < len(words):
end = start + chunk_size
chunk_words = words[start:end]
chunks.append(" ".join(chunk_words))
# Step forward by chunk_size - overlap
start += max(chunk_size - overlap, 1)
return chunksEmbedding and Search
Each chunk is converted to a vector, and queries are matched using cosine similarity:
@torch.no_grad()
def _embed_batch(self, texts: List[str]) -> np.ndarray:
inputs = self.tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
outputs = self.model(**inputs)
# Mean pooling over tokens
embeddings = outputs.last_hidden_state.mean(dim=1)
embeddings = embeddings / embeddings.norm(dim=1, keepdim=True)
return embeddings.cpu().numpy().astype("float32")
def search(self, query: str, top_k: int = 5) -> List[Dict[str, Any]]:
query_vec = self._embed_batch([query])
distances, indices = self.index.search(query_vec, top_k)
results = []
for score, idx in zip(distances[0], indices[0]):
if idx == -1 or idx not in self.metadata:
continue
meta = self.metadata[idx]
results.append({
"score": float(score),
"document_id": meta["document_id"],
"page": meta["page"],
"text": meta["text"],
})
return resultsConfiguration as a First-Class Citizen
Instead of hard-coding choices, the app uses a JSON configuration file: app_config.json.
{
"model_repo_id": "distilbert-base-uncased",
"chunk_size": 500,
"chunk_overlap": 50,
"num_search_results": 5,
"top_k": 10,
"dimension": 768
}When you change key parameters like model_repo_id, dimension, or chunking, the app prompts you to rebuild the index, ensuring the FAISS index and embeddings always stay in sync.
Experiment Ideas
Here are some concrete experiments you can run with the Context Search Engine:
1. Compare Chunk Sizes
- Try
chunk_size = 300,500, and1000 - Keep overlap constant (e.g.,
50) - Upload the same documents, rebuild index each time
- Do smaller chunks give more precise but fragmented answers?
- Do larger chunks give more context but sometimes irrelevant text?
2. Test Different Models
Switch between:
distilbert-base-uncased(fast, good starter)sentence-transformers/all-MiniLM-L6-v2(384-dim, lightweight)sentence-transformers/all-mpnet-base-v2(768-dim, high quality)
Observe query latency and relevance of results.
3. Domain-Specific Documents
Upload documents from a particular domain (medical, legal, technical, finance) and ask domain-specific questions. See how well a general-purpose model performs. This can guide you toward whether you need fine-tuning or a domain-specific model.
Challenges & Lessons Learned
Handling Context at Chunk Boundaries
Problem: Splitting text into chunks risks cutting important sentences in half.
Approach: Use overlapping chunks. The chunk_overlap parameter ensures
that adjacent chunks share some words, so relevant information near boundaries appears in more than one chunk.
Matching Models and FAISS
Problem: Different models have different output dimensions. FAISS index dimensions must match exactly.
Approach: Make dimension a required configuration parameter and validate it
against the selected model. When either changes, force a full index rebuild so the vectors and FAISS structure
remain consistent.
Balancing Speed and Quality
Problem: Bigger models and large top_k values improve result quality but increase latency.
Approach: Make top_k, num_search_results, and model choice configurable
so users can find their own speed/accuracy trade-off. On a laptop, top_k = 10 is a good starting point.
Running the Project Locally
You only need Python and pip to get started:
# 1. Clone the repo
git clone https://github.com/inboxpraveen/context-search-engine.git
cd context-search-engine
# 2. Install dependencies
pip install -r requirements.txt
# 3. Run the app
python app.py
# 4. Open in browser
# Navigate to http://localhost:5000On first run, the model will be downloaded (around ~250 MB). After that, everything runs locally.
Closing Thoughts
The Context Search Engine is not just a tool—it's a sandbox for learning how modern semantic search systems really work. You can peek under the hood, change parameters, swap models, and see in real time how those decisions affect retrieval quality.
If you're interested in information retrieval, NLP, or building intelligent document systems, cloning the repo and playing with your own documents is one of the most practical ways to get started.
"The best way to understand semantic search is to build one yourself. This project gives you all the pieces—now it's your turn to experiment."
Resources & Links
- GitHub Repository
- Full Documentation
- Sentence Transformers Documentation
- FAISS Documentation
- HuggingFace Transformers